Výzkumníci v oblasti kybernetické bezpečnosti zveřejnili několik bezpečnostních chyb, které ovlivňují open-source nástroje a rámce pro strojové učení (ML), jako jsou MLflow, H2O, PyTorch a MLeap. Tyto chyby by mohly umožnit vykonávání kódu.
Zranitelnosti, které objevila společnost JFrog, jsou součástí širší sbírky 22 bezpečnostních nedostatků, které společnost zabývající se bezpečností dodavatelského řetězce poprvé zveřejnila minulý měsíc. Na rozdíl od první sady, která zahrnovala chyby na straně serveru, nové podrobnosti umožňují zneužití klientů ML a nacházejí se v knihovnách, které zpracovávají bezpečné formáty modelů, jako je Safetensors.
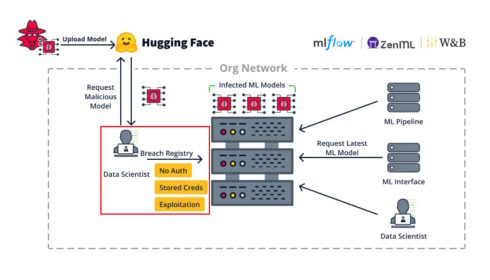
„Únos klienta ML v organizaci může útočníkům umožnit rozsáhlý laterální pohyb v rámci organizace,“ uvedla společnost. „Klient ML velmi pravděpodobně přístup má k důležitým službám ML, jako jsou registrace modelů ML nebo pipeline pro MLOps.“
To by mohlo vést k odhalení citlivých informací, jako jsou přihlašovací údaje do registru modelů, což by umožnilo škodlivému aktérovi vložit zadní vrátka do uložených modelů ML nebo dosáhnout vykonání kódu.
Seznam zranitelností je následující:
CVE-2024-27132 (CVSS skóre: 7.2)
Nedostatečná sanitizace v MLflow, která vede k cross-site scripting (XSS) útoku při spuštění nedůvěryhodného receptu v Jupyter Notebooku, což nakonec vede k vykonání kódu na straně klienta (RCE).
CVE-2024-6960 (CVSS skóre: 7.5)
Nezabezpečená deserializace v H20 při importu nedůvěryhodného modelu ML, potenciálně vedoucí k RCE.
Neidentifikované CVE
Path traversal v TorchScript funkci PyTorch, která může vést k odmítnutí služby (DoS) nebo vykonání kódu kvůli libovolnému přepsání souborů, což by mohlo být využito k přepsání kritických systémových souborů nebo legitimního pickle souboru.
CVE-2023-5245 (CVSS skóre: 7.5)
Path traversal v MLeap při načítání uloženého modelu ve formátu ZIP může vést k zranitelnosti Zip Slip, což umožňuje libovolné přepsání souborů a potenciální vykonání kódu.
JFrog upozornil, že modely ML by neměly být načítány bez důkladné kontroly, i když jsou načítány z bezpečného typu, jako je Safetensors, protože mají schopnost dosáhnout libovolného vykonání kódu.
„Nástroje pro umělou inteligenci a strojové učení (ML) mají obrovský potenciál pro inovace, ale také mohou otevřít dveře útočníkům k způsobení rozsáhlých škod v jakékoli organizaci,“ řekl Shachar Menashe, vedoucí výzkumu bezpečnosti ve společnosti JFrog. „Abychom se chránili proti těmto hrozbám, je důležité vědět, které modely používáte, a nikdy nenahrávat nedůvěryhodné modely ML, dokonce ani z ‚bezpečného‘ repository ML. V některých scénářích to může vést k vykonání kódu na dálku, což způsobí rozsáhlé škody vaší organizaci.“
Zdroj: thehackernews.com
Obrázek: JFrog
Zdroj: IT SECURITY NETWORK NEWS
Zdroj: ICT NETWORK NEWS